The purpose with this page is to provide an overview of the SSIS (SQL Server Integration Services) packages used in the ETL process managed by Analysis Models.
The ETL process means:
This is the step where data is retrieved/extracted from IFS Applications database to the stage area in the Data Warehouse in SQL Server
This step transfers data from the stage area to the DW area in the Data Warehouse in SQL Server. So it is a pure about moving data within SQL Server. Transformations and key lookup operations are performed as well during this step.
This step transfers data from the DW area to the DM area the Data Warehouse in SQL Server. The result is a set of fact and dimension tables with calculated attributes as well as technical keys, making it possible to create optimized start schema models.
The there different processing phases, i.e. the ETL, means loading data from one set of tables to another.
Each phase is based on two SSIS-templates, one related to dimensions and another related to facts.
The templates are basically built up the same way.
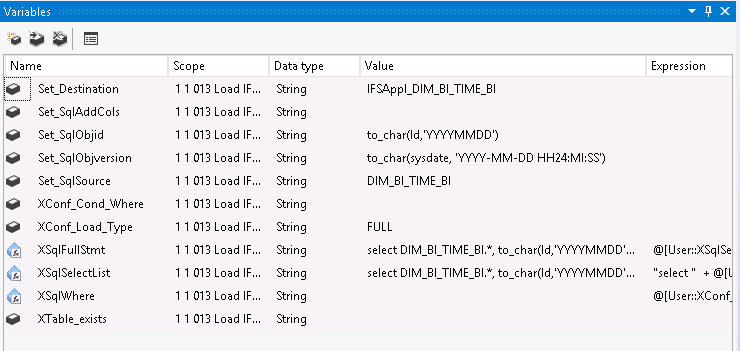
A set of variables define the source and destination objects as well as the definitions of columns, if needed, Objid, Objversion and additional calculated columns.
Variables beginning with Set are supposed to be configured by the developer.
Variables beginning with X are automatically configured and are not supposed to be changed.
Above is an example from a dimension specific SSIS package related to the dimension DIM_BI_TIME, where the BI Access View BI_DIM_TIME_BI defines the read interface.
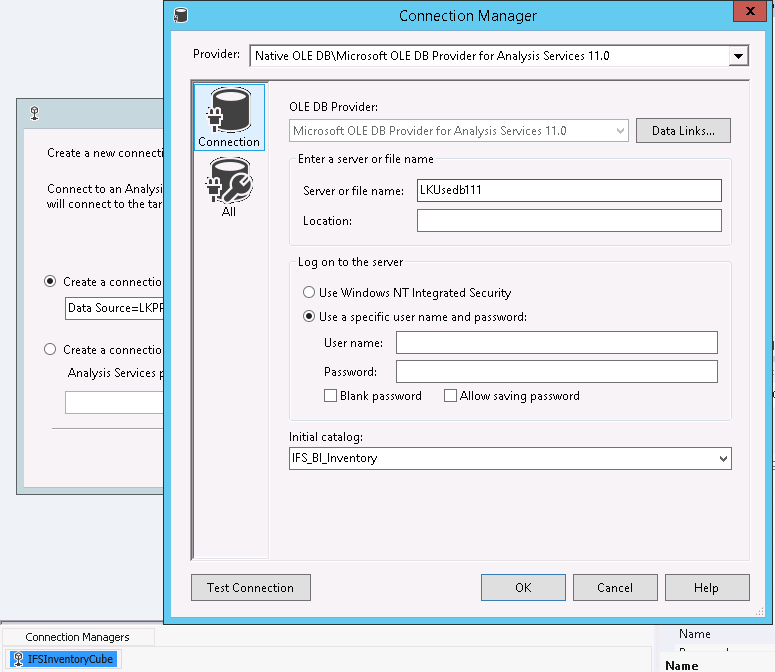
In order to access the databases a number of Connection managers are used depending on which database that is to be accessed in each step.

The IFSAppl Connection Manager defines the oracle database in which the Information Sources reside. This Connection Manager is of type ADONet.
The IFSAppl_OLEDB connector is used when checking whether the underlying *_BI views exist or not.
It points to the same database as the IFSAppl connector but is of type OLEDB.
The IFSDW connector is used when connecting to the SQL Server database.
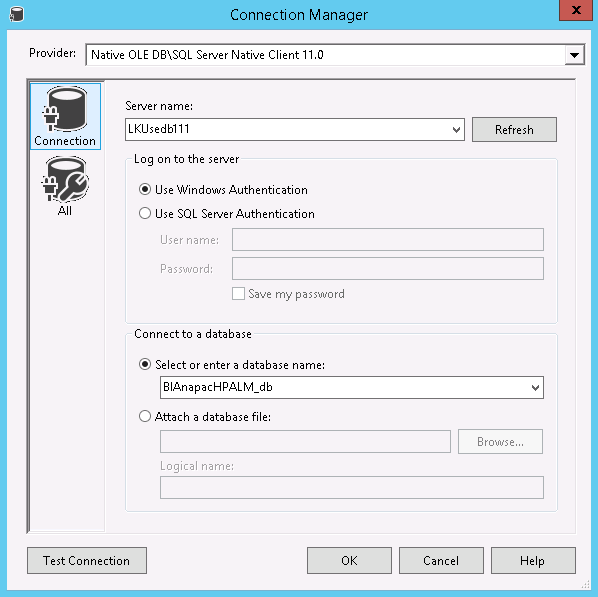
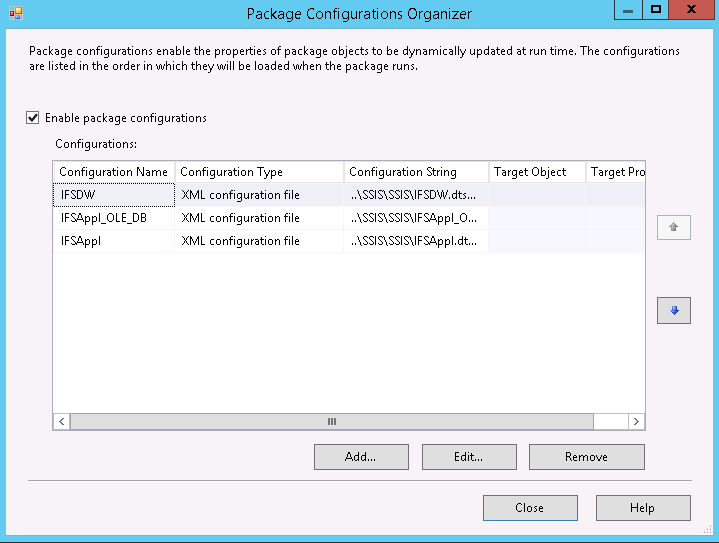
All connectors are maintained via configuration files that can be viewed and maintained under menu SSIS - Package Configurations in SSIS.
SSIS packages are named in the following manner:
Stage dimension tables
Stage fact tables
Dw dimension tables
Dw fact tables
Dm dimension tables
Dm fact tables
Process Cubes
In addition to this there are Fact component packages named 0.2.*
which are described later in this document.
The packages controlling the whole process are
0.1.000
Empty Logs which empty the SSIS logs and 0.1.001
Execute All that controls the whole SSIS flow. This
package is described separately in this document.
The extract phase takes data from Information Sources and
fills the staging area tables with data. This is where the
loading type affects the process. Variables
XConf_Load_Type and
XConf_Cond_Where are
fetched from table SSIS_PACKAGE_CONFIG
and affect the select statements in variables
XSql*.
Dimensions are supposed to be loaded as Full load so
incremental load are not supported for these tables.
Conditional load is however supported also for dimensions.
As an example you might want to use only part of the
underlying IS when it comes to only using a special interval
of the dates in the time dimension or you might perhaps only
want to include active projects.
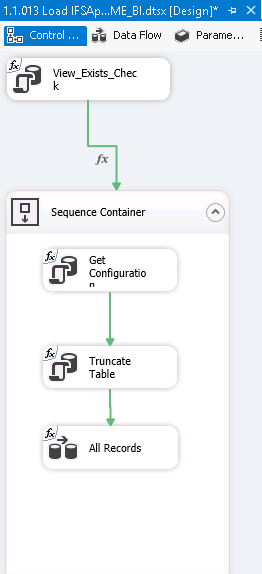
The Control Flow first checks whether the IS exist. If it
does, configurations are fetched, the Staging area table is
truncated and then data is loaded.
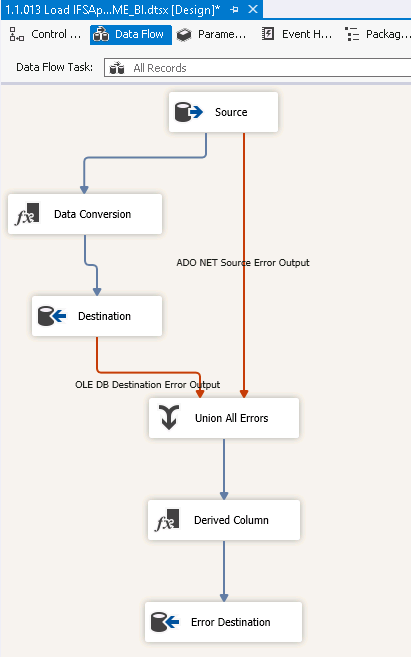
The Data Flow fetches data from the Source object, typically
adds columns Last_Loaded and
Modified_By_User (Data Conversion) and populates
the Destination table.
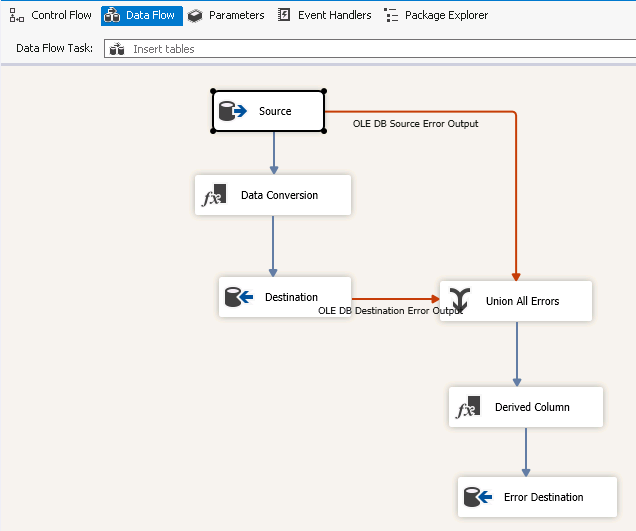
Errors are logged in table ErrorRows (Error Destination) together with some additional data (added in object Derived Column)
The transform phase takes data from the staging area and
fills the Dw area tables with data. In this step most
of the business logic is added.
The Dw* tables are always truncated before loading
takes place. After that the loading of the
Dw* tables
take place in the All Records Data Flow task.

The Data Flows for dimensions are more or less identical to the Extract phase so no further description is made here.
For facts the Data Flow is a bit different though. The data is fetched from the source component and after that the technical keys are looked up from the DM* dimension tables in Lookup objects, one for each dimension connected to the fact.
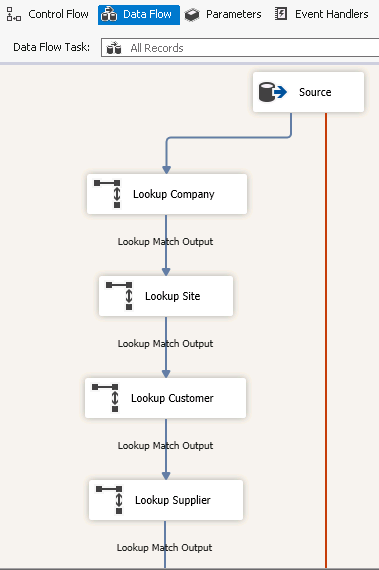
The lookup itself matches the natural keys (*IS_ID column) between the fact and dimension tables and returns the technical key (*_ID) from the dimension table.
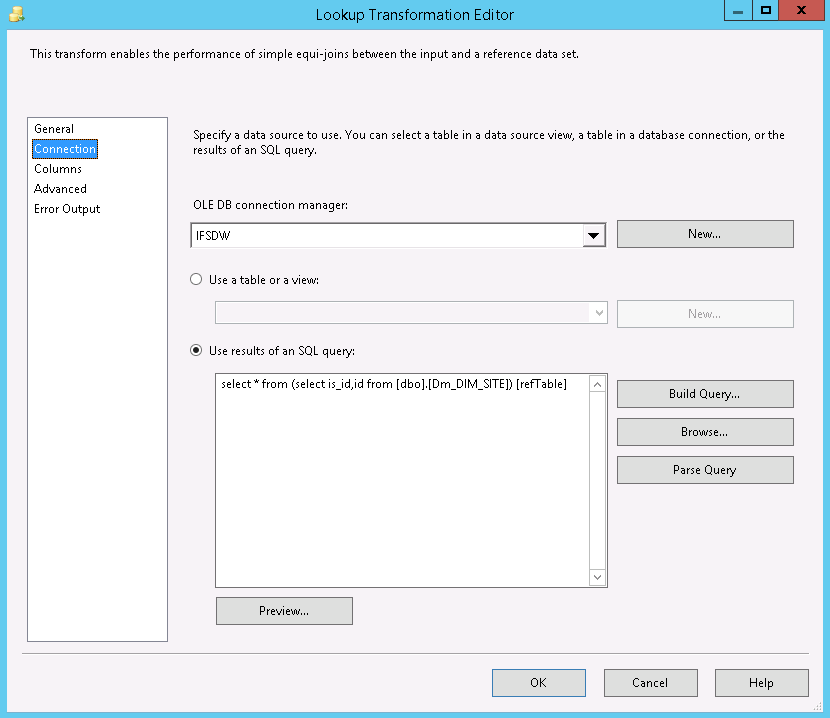
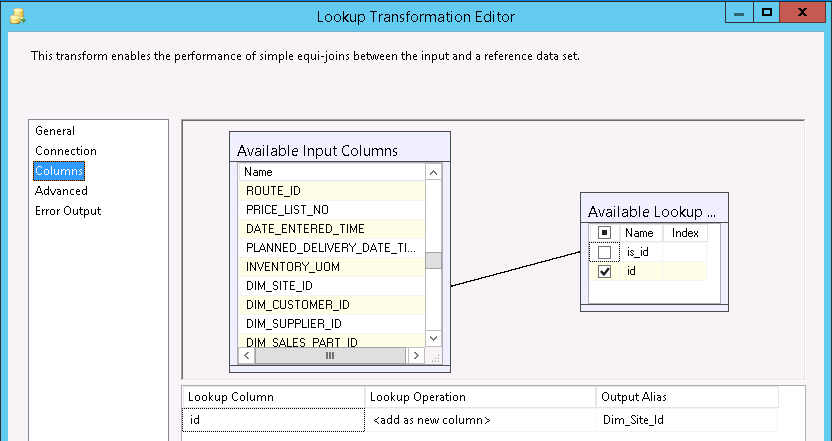
The technical key is then inserted as a new column in the flow as Dim_*_ID (See below)
For Reporting Date, it is often so that the this dimension
does not exist in core but is added in the warehouse. When
the mapping is done, using the date decided to represent the
reporting date, two out variables are created in the
transformation editor; the original key (ending with
_IS_ID) and the new
technical identity.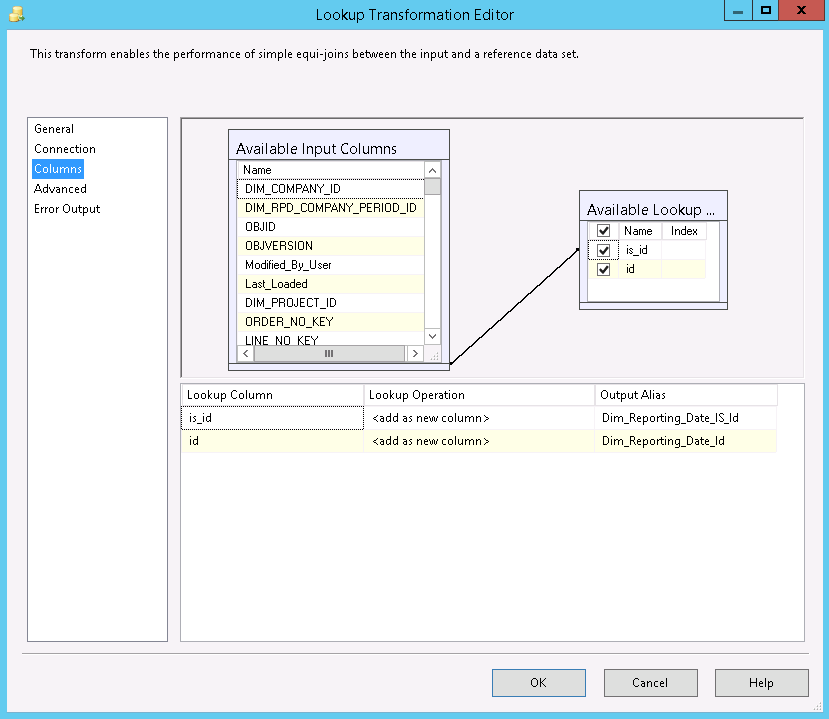
In the conversion object the Reporting date in some cases is defined as a new natural key for later lookup.
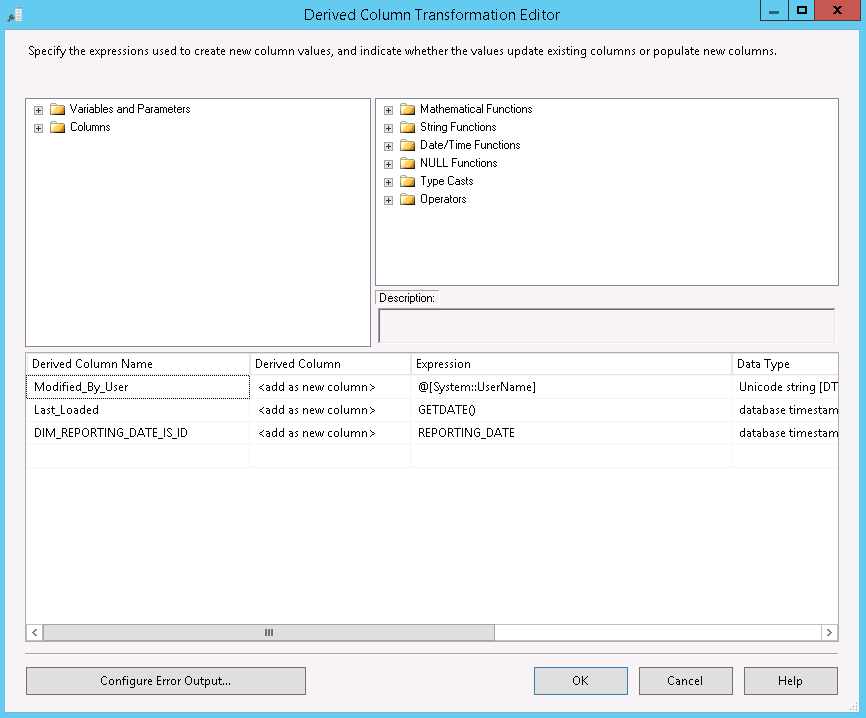
After all lookups the flow is identical to the flow of the dimension.
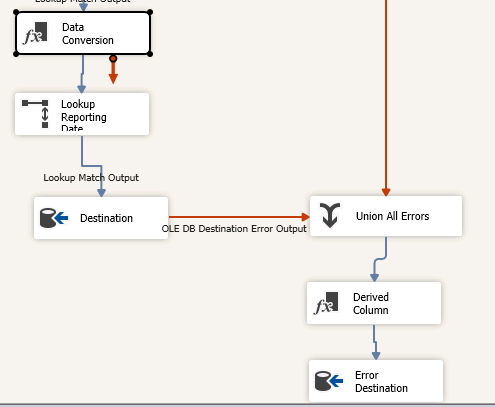
The transform phase takes data from the
Dw area and
fills the Dm area tables with data. In this step most
of the business logic is added.
In the Dm area there are double tables for dimensions as
stated before. This is done due to merging possibilities for
dimensions.
For dimensions the control flow begins with a truncation of
the temporary table where after the data flow task of
populating temporary and ordinary tables takes place (Load
All Dw Records). After that a stored procedure is called in
order to update the existing data with new data from the
previous step.
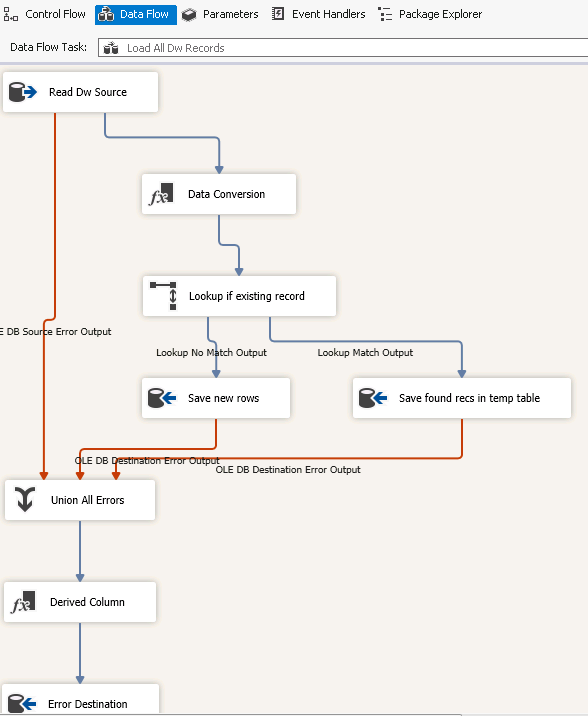
In the Data Flow task data is read from the source table and typically columns Modified_By_User and Last_Loaded are added in the Data Conversion object. After that a lookup is done to see whether the dimension object already exists. If not the new record is stored in the ordinary Dm destination table. If the record already exists the record is stored in the temporary Dm table and after that the regular error handling takes place.
For facts the process is a bit different due to the option of Incremental loading.
Three main flows are defined in the Control flow depending on the Loading configuration of the table, one for full or conditional load with truncation, one for conditional load without truncation and one for incremental load.
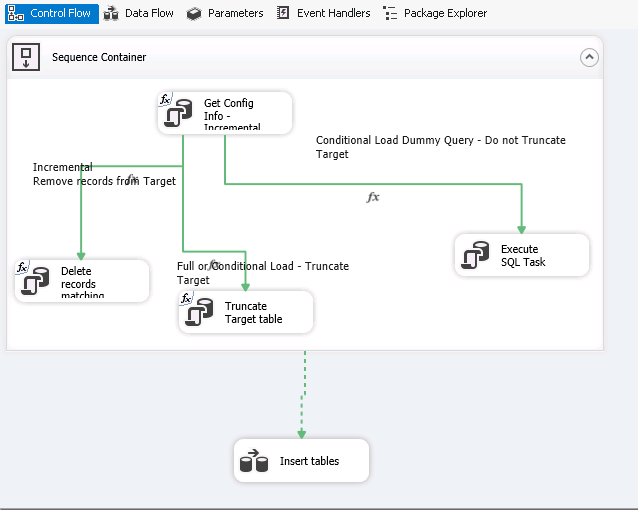
The configuration is fetched via variables XConf_LoadType giving the loading type and XConf_TypeTruncate telling whether the target table should be truncated or not. The value COND_YES tells that the loading type is full or conditional and that the target table should be truncated. The value COND_NO tells that the load type is CONDITIONAL but no truncation is done. The latter is primarily used for initial loading where you might want to load your data year by year. In this case only a dummy select is performed before loading takes place in data flow task Insert tables.
The table below shows which variables and which values that control which method that is used.
| Truncation/Loading type | Full (XConf_TypeTruncate) | Conditional (XConf_TypeTruncate) | Incremental (XConf_LoadType |
|---|---|---|---|
| Truncate | COND_YES | COND_YES | N/A |
| Do not truncate | N/A | COND_NO | INCREMENTAL |
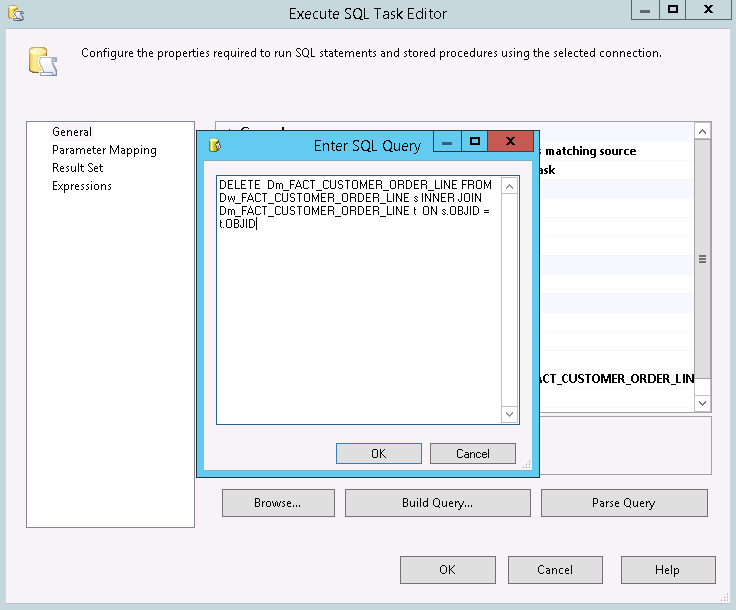
In case of incremental load the records that are to be loaded and already exist in the Dm table are deleted from the Dm table. The check is done using column OBJID.
After deletion, reading from source tables and inserting into destination tables is performed in the data flow task Insert tables. The data flow task is also designed the same way as in earlier steps and is therefore not described in detail here.
Cubes are processed in separate ETL packages. The cube is
referenced in the package.
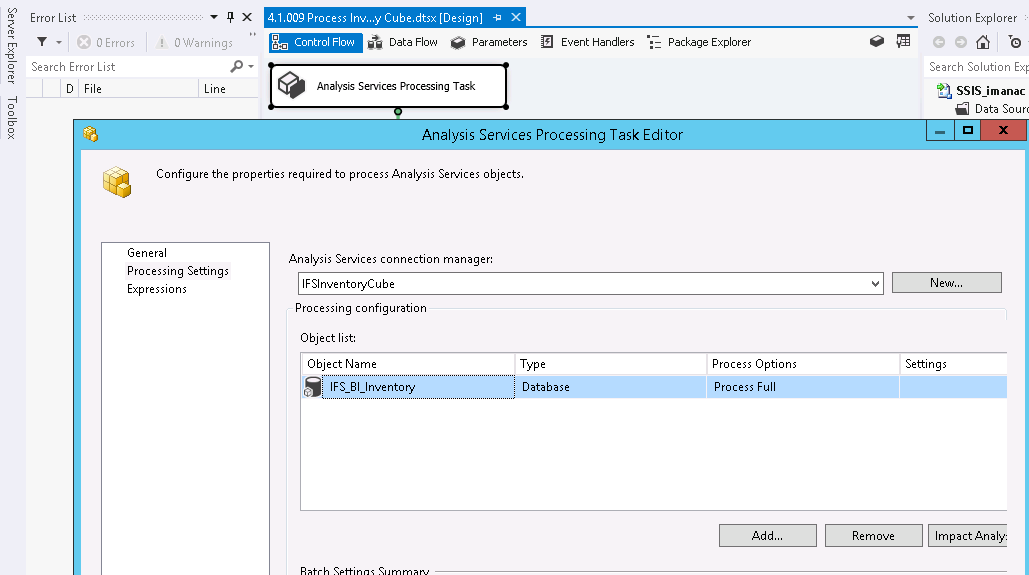
A connection manager is used to connect to the cube.
Execution of SSIS packages is done through the package Execute_All.
This package defines the loading sequence telling in which order SSIS-packages are to be executed.
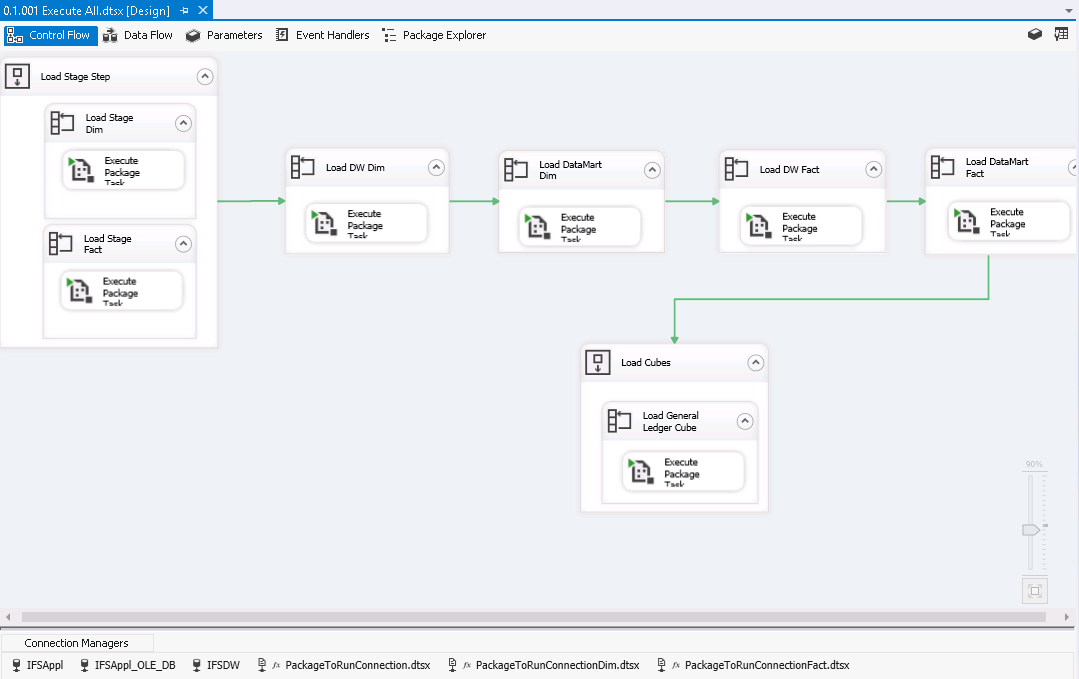
The package consists of containers and For Each loops that
reference the individual packages.
The Load Stage Step have two different For Each loops. The
Load Stage Dim executes the dimension packages in sequence.
The Load Stage Fact in turn calls fact component packages
containing their corresponding fact tables.
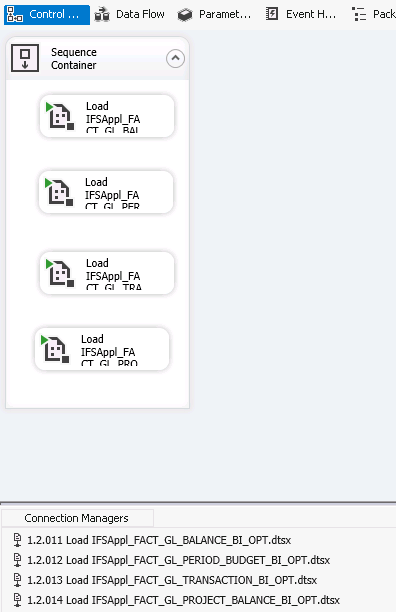
The fact component packages are run sequentially but all
fact table packages within a fact component package are run
in parallel. Fact component packages are named
0.2.0** Execute_Stage_Fact_*.
As an example Fact component package 0.2.003
Execute_Stage_Fact_genlft is run before 0.2.005
Execute_Stage_Fact_invoft.
Package 0.2.003 Execute_Stage_Fact_genlft contains
packages
These packages are executed in parallel. Each package within
the fact component package has its own Connection manager
pointing out the package to run.